Citus | Postgres 분산 데이터베이스 A-Z 소개
오랜만에 논문 한편을 읽었다.
사실 난 논문 읽는 것을 좋아한다고 하면 너무 찐인 것 같아서, 싫어하진 않는다고 말하겠다. 조직 생활을 시작하면서 대학원에서는 일상이었던 논문 리딩을 거의 하지 못했다. 마치 전공수업으로만 한 학기 다 채우다가 다음 학기에 교양과목을 들으면서 힐링하듯이, 코드만 매일 작성하다가 힐링으로 논문을 읽고 싶다고 생각했었는데, 2022년 If Kakao에서 엘라스틱 서치의 대안으로 Citus(이하 시투스라고 쓰겠음)를 쓰고 있다는 내용을 보고 난 후, 흥미가 생겨서 오랜만에 논문 한 편을 읽었다. 바로 알아가보자.

- Citus : 이 포스팅에서는 Citus를 시투스라고 표기한다. 실제 발음은 사-이투스 이렇게 하는 것 같다. 정확하진 않음
- Citus Github : https://github.com/citusdata/citus
- SIGMOD 2021' Citus : https://dl.acm.org/doi/10.1145/3448016.3457551
Citus 논문 및 저자 소개

Citus는 2021년 SIGMOD 에서 산업 트랙으로 소개된 논문이다. 제목은 Citus: 데이터 중심 애플리케이션을 위한 분산 포스트그레스큐엘 로 포스트그레스큐엘을 분산 데이터베이스로 만들었다는 것을 나타낸다. 논문의 저자들의 소속이 마이크로소프트 라고 나와 있지만, 논문의 저자들은 이전 소속이 Citus Data란 회사에서 각각 CEO, CTO 등을 맡고 있는 것으로 봐서는 마이크로 소프트로 인수되고 나서 논문으로 발표하게 된 것 같다. Citus는 발표 시기만 2021년일 뿐 사실은 예전부터 개발되고 사용되어 왔다.
왜 Citus인가?
① 왜 분산 포스트그레스큐엘(PostgreSQL) 이 필요한가?
PostgreSQL은 RDBMS의 한 종류이며 매우 강력한 커뮤니티를 가지고 있다. 주요 데이터베이스 시스템에서 사용할 수 있으며, 다양한 산업군에서 필요한 기능을 제공한다. (e.g. geospatial query, gin index 등)
PostgreSQL를 이용하는 사례가 점점 늘어나고, 데이터의 규모가 확장되면서 기존 단일 서버 구조를 수평 확장 해야 한다는 요구사항이 있었고, 그래서 우리 Citus가 이를 해내었다.
② 다른 제품들과는 무엇이 다른가?
기존 RDBMS를 분산 확장하고자 한 프로젝트는 굉장히 많았다. ( e.g. Vitess, Cockroach, Spanner 등 ), 그들은 보통 아래 3가지 접근법 중 하나를 이용해서 개발되었다.
- 새로운 데이터베이스를 만들고 기존 RDBMS와 호환되도록 드라이버와 SQL을 제공한다.
- 기존 데이터베이스를 포크해서 기능을 추가한다.
- 애플리케이션과 데이터베이스의 미들웨어 성격으로 개발해서 기능을 제공한다.
그러나 이 세 방법들은, 데이터베이스의 발전 속도를 따라가기 힘들다는 문제가 있다. PostgreSQL은 발전이 멈춘게 아니다. 새로운 SQL의 표준을 개발하고, 새로운 기능을 만들기 때문에 이것을 모두 호환하도록 만드는 것은 물리적으로 매우 어려운 일이다.
Citus는 확장 API를 이용해서 개발했기 때문에 기존 PostgreSQL의 모든 기능과 호환되면서 분산 데이터베이스를 만들었다는 것이 특징이다. 물론 데이터베이스를 분산 시키는 것이 모든 경우에 대해서 성능 향상을 시켜주는 건 아니다. 논문에서는, 아래 네 가지 경우에 해당한다면 Citus가 매우 유용할 것이라고 강조한다.
- 멀티 테넌트 SaaS 서비스
- 실시간 데이터 분석 (Real Time Analytics)
- 대규모 CRUD (High Performance CRUD)
- 데이터 웨어하우징
목차
- 시투스가 필요한 4가지 워크로드 패턴
- 우리는 이렇게 시투스를 개발했다.
- 실험 결과
- 마이크로소프트는 시투스를 어떻게 쓰고 있는가
- 결론 및 내 생각
시투스가 필요한 4가지 워크로드 패턴

위 테이블은 4가지 워크로드 패턴들의 목표 성능을 나타낸다. 차례로 다음과 같다.
- MT : Multi Tanent SaaS
- RA : Real-time Analytics
- HC : High-performance CRUD
- DW : Data Warehousing
멀티 테넌트 서비스
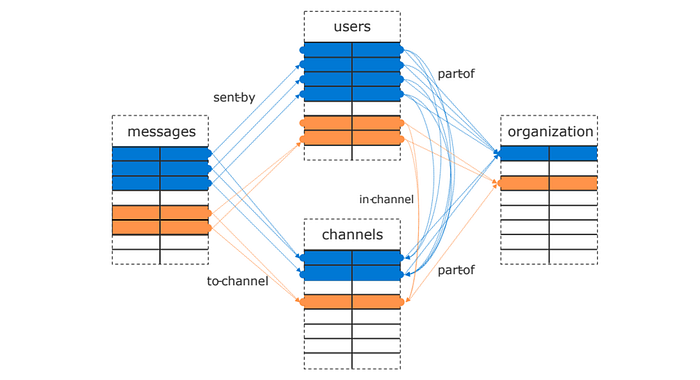
멀티 테넌트는 하나의 데이터베이스를 여러명의 고객들에게 제공하는 것을 말한다. 가장 쉽게 멀티 테넌트 서비스를 구현하는 방법은 매뉴얼하게 샤딩해서 제공하는 것이다. 조금 더 어렵게 구현한다면 모든 테이블에 Tenant-ID 라는 고객을 구분할 수 있는 컬럼을 추가해서 같은 데이터베이스에서 구분하는 것이다. 이런 방식을 이용해서 구현하려면 아래 같은 기능을 제공해야 한다.
- Tenant ID 별로 데이터가 분산되고
코로케이션(co-location)을 지원해야한다.코로케이션이란 같은 서버에 데이터가 저장되도록 분산하는 것이다. 동일한 Tenant ID별로 데이터가 인스턴스 단위로 묶이면 조인이나 각종 쿼리를 수행할 때 그 책임이 하나의 인스턴스에게 위임된다. 카프카의 파티션 키를 생각하면 좋다. - 병렬 분석 쿼리와 같은 테넌트 ID로 분산 조인을 지원해야 한다.
시끄러운 이웃에 대한 이슈 있다면, 데이터가 저장된 위치를 고객이 제어할 수 있어야 한다.- 특정 고객에 한해서만 특정 커스텀한 기능이 필요한 경우, JSONB 데이터에 필드를 추가하는 것으로 해결 할 수 있다.
- 핫스팟이 발생할 경우 어디가 병목이 되는지 알 수 있어야 한다.
그리고 Citus는 이런 기능들을 잘 제공하고 있다.
실시간 분석
실시간 분석 시스템으로는 이상 감지, 시스템 모니터링, 행동 분석, 지리/공간 쿼리, 대시보드 등이 있다. 이런 실시간 환경에서는 높은 쓰기 처리량(High write throughput) 과 대규모의 분석 쿼리를 데이터베이스가 감당할 수 있어야 한다. 쿼리는 데이터 볼륨과 상관없이 1초 이내(sub seconds) 내로 응답을 줘야 한다. 다행히도, 대 부분의 경우에서는 어떤 쿼리를 수행하는지 미리 개발자가 알 수 있기 때문에, 인덱스와 롤업(ROLLUP) 을 이용해서 응답 시간을 줄일 수 있다.
PostgreSQL은 힙 스토리지와 COPY 명령어로 데이터를 아주 빠르게 저장할 수 있고, MVCC는 분석 쿼리와 쓰기 요청이 공존할 수 있게 해준다. 또한, 배열, JSON, 커스텀 타입 등 다양한 데이터 타입을 지원한다. 단 하나, PostgeSQL 혼자 못하는 것은 이런 대규모의 데이터를 저장하면 쉽게 단일 서버의 용량을 넘긴다는 것 뿐이다. 그래서 Citus는 아래 기능을 제공해서 PostgreSQL이 실시간 분석 시스템에서 활용 될 수 있게 돕는다.
- 실시간 분석 워크로드를 감당하려면 데이터베이스 스스로 데이터를 여러 서버로 분산시키고, 병렬로 벌크 로딩을 할 수 있어야 한다.
- 소스 테이블과 롤업 테이블간 코로케이션은 INSERT와 SELECT 구문을 매우 효율적으로 처리할 수 있게 해준다.
- 쿼리는 query routing, parallel, 분산 SELECT 등을 사용해서 응답 시간을 줄인다.
- 후반 장에서 마이크로소프트에서는 어떻게 Citus로 페타바이트 스케일의 실시간 분석을 수행하는지 보여준다.
대규모 CRUD
단일 서버의 PostgreSQL는 대규모 CRUD 요청을 받기 힘들다.
- PostgreSQL은 MVCC 모델 떄문에 CRUD 할 때 추가적인 비용이 발생한다. MVCC에서는 트랜잭션 마다 스냅샷으로 과거 버전의 튜플을 생성하게 되는데, 시간이 지나서 사용하지 않는 버전은 주기적으로 삭제해야 한다. 그래서, 가비지 컬렉션을 통해 안 쓰는 버전을 주기적으로 삭제하는 Auto-vacuuming 기능이 있다.
- 만약 Auto-vacuuming으로 튜플을 제거하는 속도보다 더 빨리 쓰기 요청이 들어와서 튜플이 쌓이면 심한 병목이 발생한다.
- Process-per-request 모델이기 때문에 단일 서버에서는 많은 사용자의 요청을 받기 힘들다.
이를 해결하는 시투스의 방법은 단순하다. 분산 키를 기준으로 테이블을 각 워커로 분산시켜서 CRUD 성능을 높인다. 쿼리 종류에 따라 어느 샤드에서 데이터를 가져올 지 매우 빠르게 결정하고 가져올 수 있다. 또한, Auto-vacuuming이 모든 코어에 대해서 병렬적으로 작동하게 된다.
데이터 웨어하우스
데이터웨어 하우스는 보통 조직에서 애플리케이션 레이어와 독립적으로 구축해서 분석 쿼리를 날리는 곳을 지칭한다. 데이터 웨어하우스는 보통 레이턴시나 목표 성능이 없는 것이 특징이지만, 대용량의 데이터를 빠르게 쿼리할 수 있어야 하고 쿼리 플랜도 효율적으로 만들어줘야한다.
논문에서는 솔직히 AWS Redshift나 다른 웨어하우스 전용 서비스들이 훨씬 성능이 높다고 고백한다. 다만, PostgreSQL로도 충분히 할 수 있는 일이고 조금 느려도 된다면 Why not? 이라는 질문을 던진다.
데이터 웨어하우징 서비스를 스케일 업을 하려면 아래 기능이 필요하다.
- 병렬 처리, 분산 SELECT, 컬럼 기반 저장이 지원되어야 한다.
- 분산 컬럼 저장은 co-located 분산 조인을 할 때 매우 효율적이다.
- 그러나, 데이터베이스는 non-co-located된 조인도 지원해야한다.
- 쿼리 optimizer가 조인의 실행 순서를 네트워크 트래픽을 줄이도록 결정해줘야 한다.
Citus는 지금 대부분의 기능을 지원하나, non-co-located join 에 대해서는 몇 가지 한계가 있다고 한다.
우리는 이렇게 시투스(Citus)를 개발했다.
여기서부터는 논문에서 어떻게 시투스를 개발했는지, 시투스는 어떤 구조를 가지고 있는지 설명한다.
강력한 확장 API
PostgreSQL이 커뮤니티로부터 엄청난 호응을 받을 수 있던 이유 중 하나는 아마 확장 API 때문일 것이다. 확장 API는 데이터베이스의 원본 코드를 고치지 않더라도 기능을 추가할 수 있게 제공한다. 시투스는 이 확장 API를 이용해서 만들어 졌기 때문에 PostgreSQL의 대부분의 기능과 호환된다. 단순하지만 매우 강력한 특징이다.
PostgreSQL은 파서 빼고는 모든 것이 모듈식 구조로 구성되어 있어서 거의 모든 부분에 커스텀한 기능을 추가할 수 있다.
- UDF ( User-defined functions ) : 프로시저 같은 커스텀 함수
- Planner and executor hooks : 쿼리 플랜에 훅을 걸어서 쿼리를 갈아 끼운다거나 덧 붙이는게 가능하다.
- CustomScan : 데이터를 스캔하는 방식을 결정하고 결과를 리턴하는 플랜으로 커스텀하게 만들 수 있다. 시투스에서는 다른 서버로 쿼리를 전송하는 서브 플랜을 생성하고 그 결과를 취합하는 용도로 만들었다.
- Transaction Callbacks — 트랜잭션에서 어보트, 프리 커밋, 포스트 커밋 등 중요한 지점마다 실행되는 콜백함수이다. 분산 트랜잭션을 구현할 때 쓸 수 있다.
- Utility Hooks — 일반 쿼리 플래너에서 잡히지 않는 명령어들이 호출되는 곳이다. DDL이나 COPY 명령어를 위해 쓴다고 한다.
- Background Workers — 사용자가 정의한 코드가 별도 프로세스에서 실행된다. 분산 데드락 감지, 2PC를 위한 복구 등에 쓰인다.
이걸 다 활용하면 바로 너, 여러분도 시투스를 만들 수 있다.
시투스 아키텍처
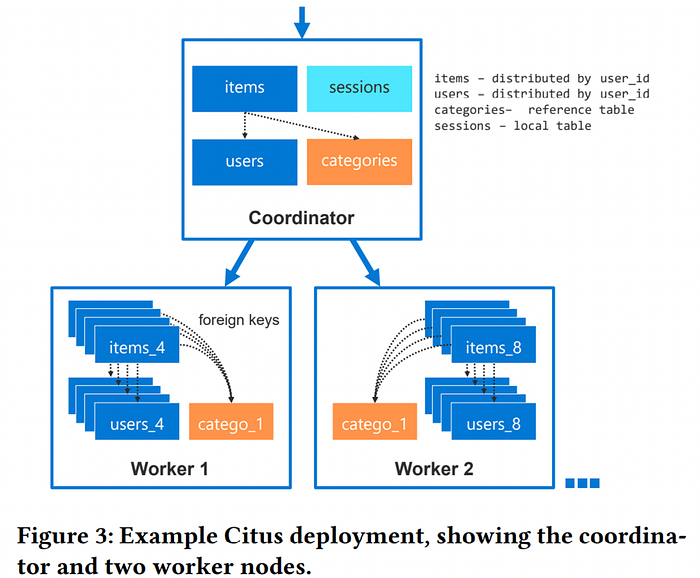
위 그림은 기본적인 시투스 아키텍처를 나타낸다. 아키텍처는, 하나의 코디네이터(Coordinator)와 다수의 워커 노드(Worker-node)가 존재한다. 시투스를 처음 설치할 때 서버 하나를 추가하면 자동으로 코디네이터가 된다.
우리가 데이터베이스를 이용하려고 DSN을 입력해서 연결을 맺는다면, 코디네이터의 주소를 이용해야 한다. 코디네이터는 1️⃣ 사용자의 요청을 받아서 쿼리 플랜을 만들고, 각 워커노드로 요청을 내린다. 2️⃣ 필요에 따라서는 분산 트랜잭션을 실행하고 2PC의 라이프 사이클을 책임진다. 3️⃣ 각 워커노드로 어떤 데이터를 저장할지 결정하고 필요에 따라 리밸런싱을 수행하는 주체이기도 하다 워커 노드는 실제로 데이터를 샤드 단위로 저장하는 역할을 한다. 코디네이터로 부터 받은 쿼리 명령을 수행하고 결과를 코디네이터로 전송한다.
클러스터가 작은 경우엔 코디네이터가 혼자 워커노드의 역할 까지 담당한다. 그래서 시투스 클러스터의 가장 작은 단위는 노드 1대 이다.
Q. 코디네이터가 병목이 될 수 있지 않나?
A. 코디네이터가 관리하는 메타 데이터를 전부 워커 노드로 복제하고 모든 워커노드를 코디네이터로 만드는 옵션이 있다고 한다. 이 경우엔 클라이언트 사이드에서 로드 밸런싱을 다수의 워커 노드에 걸어서 사용해야 한다.
일단 논문에서는 이 옵션을 되도록이면 사용하지 말라고 말한다. 그 이유는 각 노드를 코디네이터로 만들고 서로, 서로 연결을 맺어야 하는 분산 트랜잭션을 계속 날리면 커넥션 수가 부족하고 오히려 병목이 된다고 한다.
시투스의 데이터 타입 ❗️❕
사실, 시투스를 이용하는 애플리케이션 개발자 입장에서는 이 내용이 가장 중요하다. 시투스는 분산 테이블과 레퍼런스 테이블, 이 2가지 데이터 타입을 지원한다.
분산 테이블
분산 테이블은 분산 컬럼 항목에 대해서 해시 파티션을 수행해서 각 샤드에 논리적으로 배치하는 것을 말한다. 해시 파티션을 이용하면 샤드 간에 리밸런싱을 자주 하지 않아도 데이터 분산이 고르게 잘되고 locality를 줄 수 있다. 예를 들어 유저 키를 분산 컬럼으로 지정하면 동일한 유저의 데이터는 동일한 샤드와 워커 노드에 저장될 것이다.
분산 테이블을 만들 때 코로케이션(co-location)을 지정할 수 있다. 코로케이션이란 서로 다른 테이블에 저장된 데이터가 동일한 워커 노드에 저장되었으면 좋겠다고 선언하는 것이다.
CREATE TABLE other_table (...);
SELECT create_distributed_table(
'other-table',
'distribution_column', colocate_with := 'my_table'
);- 서로 다른 테이블의 데이터에서 유저 키 단위로 같은 노드에 저장 되도록 코로케이션을 설정한다면? 조인 쿼리를 날릴 때 부가적인 네트워크 통신 없이도 데이터를 조회 할 수 있게 된다.
레퍼런스 테이블
모든 워커노드에 복제되는 테이블을 레퍼런스 테이블이라고 부른다. 마찬가지로 조인이나 각종 쿼리에 있어서 디펜던시를 가지고 있을 때 유용하다.
CREATE TABLE dimensions (...);
SELECT create_reference_table ('dimensions');- 만약 레퍼런스 테이블에 쓰기 요청을 보내면, 모든 노드에 대해 새로 씌여진 데이가 복제된다.
데이터 리밸런싱
잘 운영되고 있는 클러스터에 용량이 부족해서 새로운 워커 노드를 추가하고 싶을 수 있다. 혹은 애플리케이션 특성에 따라 핫스팟이 발생할 수 있다. 시투스는 필요한 경우 샤드 리밸런서가 샤드를 각 노드간 재배치를 수행한다. 샤드가 재배치 되고 있는 와중에도 read/write 요청은 그대로 수행이 가능하다. 새로운 워커노드가 기존 샤드를 모두 복제하고 나서 요청을 모두 위임받게된다.
분산 쿼리 플래너
쿼리를 날리면 플랜에 따라 3가지 종류로 나뉜다.
- Fast path planner
- Route planner
- Logical planner
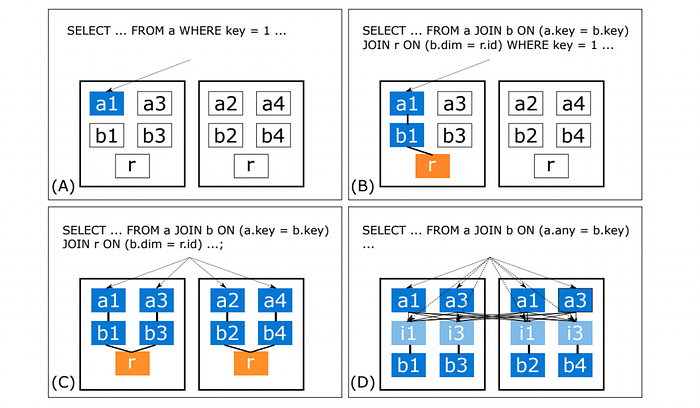
- (A) Fast path planner
분산 키로 데이터가 분산되기 때문에 어느 노드의 몇 번 샤드에 저장된 데이터를이미 알고 있다. 그래서 바로 해당 워커 노드로 요청을 보낸다. - (B) Router planner
co-location된 테이블 간에 조인 쿼리를 날리는 경우를 말한다. 같은 워커 노드 안에 서로 다른 샤드간 조인을 수행하는 그림을 (B) 에서 볼 수 있다. - Logical Planner
(A), (B)는 하나의 노드에서 요청 처리가 가능하기 때문에 표준 SQL을 그대로 사용할 수 있지만, 만약 노드 끼리 데이터를 교환하면서 조인을 걸어야 한다면 조금 애매해진다. - (C) Logical Pushdown Planner
그림 C 처럼 각 노드에 데이터를 따로 조회하고 위에서 취합할 수 있는 경우를 Pushdown Plan 이라고 부른다. 예를 들어SELECT .. FROM .. GROUP BY KEY와 같은 쿼리에서 KEY를 분산 키로 잡은 경우이다. - (D) Logical join order planner
만약, GROUP BY KEY에서 KEY가 분산 키가 아니라면? 그림 D처럼 여러 노드에 걸쳐서 데이터를 주고 받아야 할 것이다. 비록 시투스에서는 이런 경우에도 데이터를 조회할 수 있게는 해주지만, 당연히 성능은 저하되기 때문에 이런 경우는 최대한 피해야 할 것이다.
분산 쿼리 실행

만약, Logical Pushdown Planner 처럼 여러 워커노드에 걸쳐서 쿼리 요청을 보내고 데이터를 받아야 하는 경우에는 Adaptive Executor라는 서브 플랜을 만든다. 논문에서는 Adaptive Executor의 성능을 높이기 위해 slow start 라는 알고리즘을 좀 더 소개하는데 여기서는 커넥션을 관리하는 알고리즘이라고만 말하고 스킵하겠다.
slow start : Adaptive executor가 만들어 질 때마다 커넥션을 새로 맺으면 매우 느리고, 그렇다고 커넥션을 만들어 놓고 대기하면 트래픽이 없을 때는 커넥션이 놀고 있을 것이다. 그걸 관리하는 방법이다.
분산 트랜잭션
시투스는 분산 트랜잭션을 제공한다. 그래서 트랜잭션 기능을 편하게 이용하면 된다.
- Single Transaction : 만약 트랜잭션을 처리하는 주체가 워커 노드 한대라면 일반 트랜잭션처럼 처리하면 될 것이다.
- 2PC(Two-phase Commit) : 시투스 분산트랜잭션은 2PC를 이용한다.
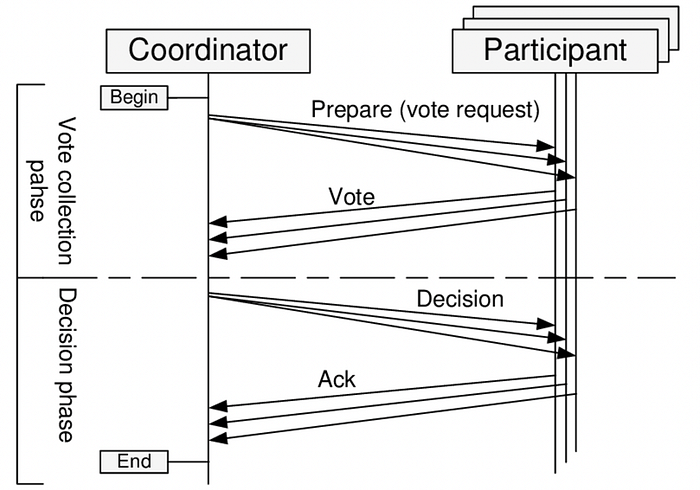
2PC는 단순히 코디네이터가 모든 워커 노드로 요청을 보내고 투표를 받아서 처리하고, 그 결과를 커밋하는 방식을 말한다. 데이터 중심 애플리케이션 설계 라는 책에서는 2PC를 결혼식에서 주례사가 신랑 신부에게 이 결혼을 동의하냐는 질문을 하고 응답을 받으면 결혼이 성사되었다고 말하는 과정에 비유한다.
2PC가 모든것이 잘 동작하는 해피 패스에서는 유용하나, 장애 상황이 발생하면 매우 까다롭기 때문에 이에 대한 대비가 필요하다. 아래는 2PC 분산 트랜잭션의 제약사항을 나열한 것이다.
- 코디네이터의 구현은 보통 고가용성을 제공하지 않거나 기초적인 복제만 지원하기 때문에 단일 장애지점(SPOF)가 된다.
- 보통 서버는 Stateless로 많이 개발해서 확장과 축소를 할 수 있는 이점이 있다. 그러나, 코디네이터가 애플리케이션의 일부가 되면 배포의 성격이 바뀌게 된다. 이렇게 되면 서버는 더 이상 Stateless로 개발 할 수 없다. -> 시투스에서는 상관없다.
- XA는 광범위한 데이터 시스템과 호환되어야 하며, 여러 시스템에 걸친 교착 상태를 감지할 수 있어야 하기 때문에 PostgreSQL의 SSI를 지원할 수 없다.
- 2PC는 모든 참여자의 응답이 필요하므로, 시스템 중 어느 하나라도 고장나면 트랜잭션이 실패한다. 따라서, 분산 트랜잭션은 장애를 증폭시키고 내결함성을 지키기 어렵다.
분산 교착 상태 감지
교착상태(dead-lock)은 서로가 서로에게 필요한 자원을 달라고 하는 상황을 말한다. 시투스 처럼 분산 시스템에서는 재수 없으면 아래와 같이 분산된 형태의 교착 상태가 발생할 수 있다고 한다.
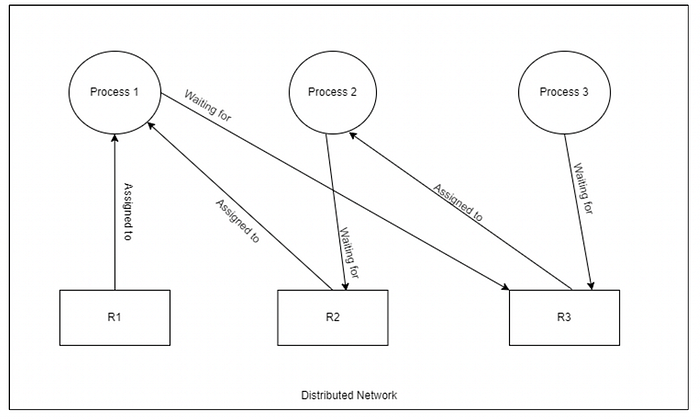
트랜잭션을 계속 날리다가 분산 교착상태가 발생한다면 연결된 트랜잭션 중 하나를 취소(Abort) 시켜야 한다. Google의 Spanner나 Cockroach DB는 wound-wait 라는 알고리즘을 사용한다고는 하는데 시투스는 단순한 방법을 선택한다.
주기적으로 모든 워커 노드에게서 락이 걸린 관계 A -> B를 받는다. 코디네이터에서 이를 그래프로 만드는데 만약 사이클을 형성한다면 사이클이 되는 간선 중에서 하나를 선택해 해당 트랜잭션을 취소 시킨다.
다중 노드에 걸친 트랜잭션의 한계
시투스에서 분산 트랜잭션은 원자성, 일관성, 영속성은 지키지만 스냅샷 격리 보장 은 안된다.
- 정보에 대해 쿼리를 할 때 MVCC 튜플이 커밋되기 전인지, 커밋된 후인지 판단하면서 트랜잭션을 보내는게 아니기 때문이다.
- 근데 시투스를 흔히 쓰는 4가지 워크로드 패턴을 보면, 다행이도 이런게 필요한 상황은 그닥 많진 않더라고 논문에서는 말한다.
고가용성과 백업 (HA and Backup)
고가용성(HA)
기본적으로 PostgreSQL의 기본 복제 기능을 이용한다.
- 리더 / 팔로어 서버가 존재하고, 리더의 쓰기 전 로그(WAL)을 가지고 동기, 비동기, 쿼럼 복제를 선택해서 수행한다.
- 장애 상황에서 리더가 떨어지면, 팔로어가 리더로 승격된다. 이렇게 failover 과정은 대략 20–30 초 정도 걸린다고 한다.
백업
논문에서는 백업도 지원한다고 하는데, 시투스 클러스터를 대규모로 운영하면 백업이나 복구가 쉽지는 않을 것 같다. 논문을 읽어봐도 무슨 소린지 제대로 이해를 못해서 여기서는 그냥 적지 않겠다.
성능
지금부터 논문에서 소개한 성능 지표를 차례로 후려쳐서 소개할 것이다. 먼저, 성능 지표의 대략적인 기준은 아래와 같다.
성능 측정 기준
- 모든 DB는 Azure Virtual Machine 을 사용함
- 16 vcpus / 64 GB memory / 7500 IOPS
- PostgreSQL 13 , Citus 9.5 버전을 사용하고 기본 설정 값을 이용함
비교군
- PostgreSQL : 단일 PostgreSQL DB
- Citus 0+1 : Citus 한대
- Citus 4+1 : 코디네이터 1개, 워커 노드 4개
- Citus 8+1 : 코디네이터 1개, 워커 노드 8개
개인적으로 데이터 비교군이 4개 밖에 없는게 아쉽다. 마이크로소프트면 돈 좀 더 써서 워커노드 16개, 32개, 64개 등 비교 집단을 늘려보지.. 8개는 이것만 보고 데이터베이스를 선택하기에는 조금 부족한 데이터라고 느껴졌다.
① 멀티 테넌트 서비스
- HammerDB 라는 DB 벤치마크 도구를 씀
- HammerDB 3.3을 이용해서 500개의 데이터 하우스(100GB)와 250개의 가상 유저(connection)을 설정함
- 1ms 마다 트랜잭션이 날아가고 1시간 동안 수행된다.
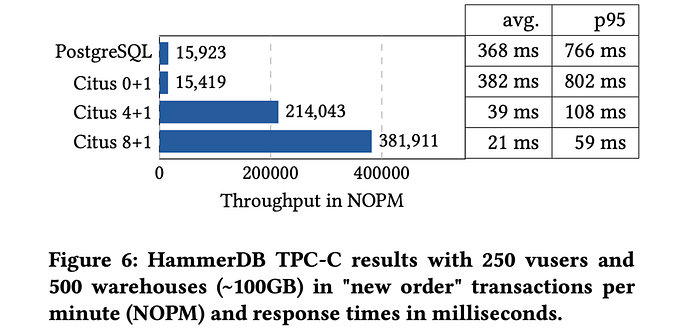
시투스를 1대만 이용할 경우는 PostgreSQL 1대를 이용하는 경우보다는 무조건 느리다. 쿼리 플랜이 더 추가되었기 때문에 오버헤드가 있기 때문이다. 그렇지만 클러스터에 워커 노드를 4대만 추가해도 1대의 경우보다 13배의 성능 향상이 있었다고 한다. 물론 그 이후부터는 8개로 노드를 늘려도 sub-linear 하게 증가했다고 한다.
② 분산 트랜잭션 성능
50GB의 데이터를 일단 생성해본다.
BEGIN TRANSACTION;
UPDATE a1 SET v = v + :d WHERE key = :key1;
UPDATE a2 SET v = v + :d WHERE key = :key2;
COMMIT TRANSACTION;위 쿼리에서 key1, key2를 랜덤으로 생성해보면서 트랜잭션을 날려보면서 성능을 측정했다고 한다. 아래 그림에서 Same Key는 키가 동일해서 하나의 워커 노드에서 처리가 가능한 트랜잭션이다. 키가 다른 경우에는 분산 트랜잭션으로 실행되는 경우가 된다. 실험 결과 분산 트랜잭션이 약 20~30% 정도 느리다고 한다.
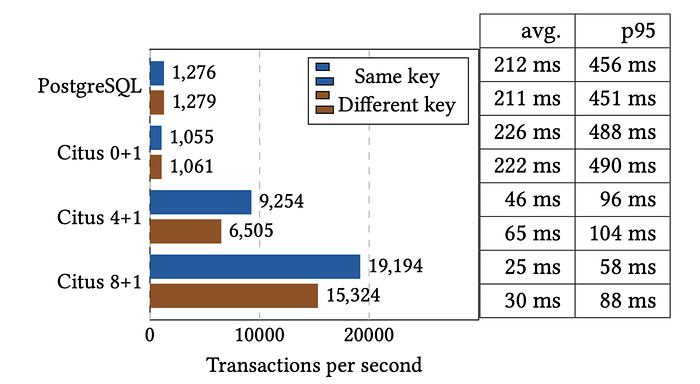
주요 포인트는, 그래도 노드를 늘리면 스케일 아웃은 된다는 점이다.
③ 실시간 벤치 마크
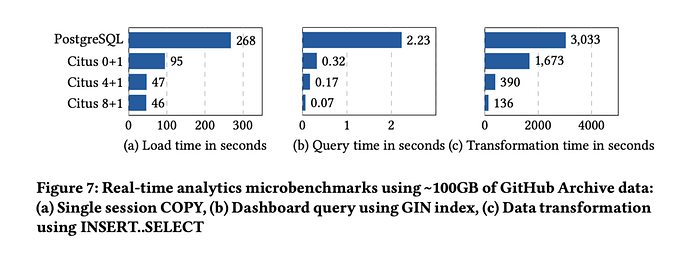
깃허브에서 공개한 데이터를 기준으로 실험했다고 한다. 단순하게 말해서 시투스가 성능이 좋았다고 한다.
④ 대규모 CRUD 측정
YCSB 데이터 측정 도구를 이용해서 미리 1억 건의데이터를 저장하고, 1시간 동안 256개의 스레드로 절반의 쓰기 요청과 절반의 읽기 요청을 보내면서 측정했다.
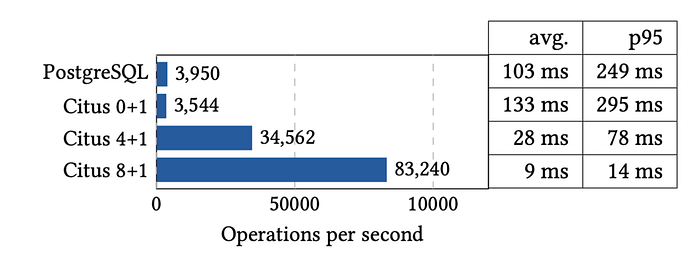
특히 CRUD 같은 경우는 하나의 워커 노드에 위임하는 비율이 높을 것이라서 성능 체감이 잘될 것 같다. 분산 트랜잭션을 쓰는 경우라면 그렇게 드라마틱한 성능 향상은 기대하지 못할 수도 있다. 그리고 CRUD처럼 단순한 요청이 아니라 비즈니스가 조금 복잡한데 강력한 일관성 모델이 필요한 경우라면 시투스를 쓰기 어려울 수도 있다. 그래서 토스의 코어 뱅킹 서버도 데이터베이스 1대로 이루어져 있다고 한다.
그리고 데이터 웨어하우징에 대한 실험 결과도 논문에 나오는데, 똑같이 성능 좋았다라고 반복하고 있어서 여기서는 스킵한다.
마이크로소프트는 시투스를 어떻게 쓰고 있는가?
마이크로스프트는 시투스를 윈도우즈 데이터를 분석하는데 쓰고 있다. 만약 여러분이 윈도우 PC를 키고 데이터 공유를 허용했다면 시투스 데이터베이스로 메트릭이 전송되고 있을지도 모른다
- 1억개 이상의 Window 장비에 걸린 텔레메트리를 수집해오고 수집된 메트릭을 RQV라고 불리는 실시간 분석 대시보드로 만든다.
- RQV : Release Quality View
- RQV는 윈도우 개발팀이 고객 경험을 평가할 때 쓴다.
VeniceDB
- RQV 데이터를 저장하는 DB를 VeniceDB 라고 부르고 있다.
- Azure에서 1000개 이상의 시투스 클러스터로 구성되어 있다.
VeniceDB를 초기 설계할 때 많은 분산 DB와 데이터 처리 시스템을 고려했는데 최종적으로는 시투스를 쓰게 되었다고 한다. 이유는 아래와 같음 👇
- 10TB 이상의 데이터를 소화 해냄
- p95(백분위 95%) 에서 1초 미만으로 응답을 준다. 이런 걸 매일 600만 쿼리 이상을 수행 중
- RQV에 20분 내로 새로운 정보를 보여줄 수 있다.
- 카디널리티를 높게 group by를 걸면 nested subquery도 가능
- GiST, partial index 등 원하는 거 걸 수 있음
- 배열, HyperLogLog 같은 고급 데이터 타입도 쓸 수 있음
- 기타 등등
결론 및 내 생각
오랜만에 논문을 읽고 한 번 가볍게 정리해 보았다. 시투스는 강력한 분산 데이터베이스 시스템으로 수평 확장이 된다는 것(비록 sublinear하게 증가하지만)과 PostgreSQL과의 호한성을 가진다는 점에서 매력적인 시스템이다.
하지만, 현실적으로는 Managed DB 형태의 서비스를 Azure에서만 제공한다는 점 때문에, AWS나 다른 클라우드를 주로 쓰는 팀이라면 회사가 전폭적인 지원(DBA도 붙여주고, DevOps도 붙여주고..)을 해주지 않는다면 실제로 사용해보기에는 매우 어려울 것 같다.
데이터 웨어하우스 처럼 구축 하면서 조금 잘 안되거나 망가져도 실제 서비스에 영향을 주지 않으면 시도 해볼만 할텐데 실제 비즈니스와 연동되는 로직을 시투스로 쓴다면 리더의 결단과 많은 검증이 필요해 보인다.

